Step 1. Preprocessing

With TRACER you can perform two types of preprocessing, letter-level and word-level processing.
Letter-level preprocessing
Letter-level preprocessing can be useful to, for example, process scriptura continua (=continuous script), a style of writing used in antiquity without spaces or marks between words, or to detect patterns of letters, such as alliteration. The letter-level preprocessing section of tracer_config.xml contains the following properties, which you can activate or deactivate depending on the type of detection you need to run:

- If the value of
boolReplaceWhitespacesis set totrue, TRACER will add whitespaces in a specified interval of characters. The interval is specified in the next property,intNGramSize. - The value of
intNGramSizeis a number (intstands for integer), and defines the word-size in characters. If the value is5, TRACER will add a space every 5 characters, for example:ABCDEFGIHJwill becomeABCDEFGHIJ. - If the value of
boolRemoveDiachritics(sic!) is set totrue, TRACER will remove all diacritics from your text (assuming you're working with languages that have diacritics, such as Ancient Greek). - If the value of
boolMakeAllLowerCaseis set totrue, TRACER will transform all uppercase letters in your text to lowercase.
Word-level preprocessing
Word-level preprocessing is the default preprocessing technique and it is used to process words. The word-level preprocessing section of tracer_config.xml contains the following properties, which you can activate or deactivate depending on the type of detection you need to run:

- If the value of
boolLemmatisationis set totrue, TRACER will reduce all words in a text to the base-form list provided by the user in theBASEFORM_FILE_NAMEproperty. - If the value of
boolReplaceSynonymsis set totrue, TRACER will compare all words in a text to the synonyms list provided by the user in theSYNONYMS_FILE_NAMEproperty. - If the value of
boolReplaceStringSimilarWordsis set totrue, TRACER will swap a word with a similar word in the text(s), where "similar" means character-similarity. In every detection task TRACER always computes assimfile with a list of string-similar words. Here is an example entry from assimfile generated on Latin texts:abiectionem obiectiones 8 0.8. TRACER here tells us that these two words have 8 letters in common (b,i,e,c,t,i,o,n,e) and are therefore 80% similar to one another (0.8 = 80%) [NB: TRACER always counts from 0, not 1]. If the value of this property is set totrue, TRACER will replace the first word with the second word. - If the value of
boolRemoveDiachritics(sic!) is set totrue, TRACER will remove all diacritics from your text (assuming you're working with languages that have diacritics, such as Ancient Greek). - If the value of
boolMakeAllLowerCaseis set totrue, TRACER will transform all uppercase letters or words in your text to lowercase. - If the value of
boolReplaceWordByWordLengthis set totrue, TRACER will replace all words with a number representing their length in characters (so, the word HOUSE would become 5).
[warning] To update.
If the value of
boolReplaceByReducedStringis set totrue, TRACER will...
- The value of
intMinWordLengthThresholdis tied to theboolReplaceStringSimilarWordsproperty and defines the minimum word length (in characters) that both words have to have in order for the replacement to happen. The default number is set to5characters but it can be changed to any value. This feature is language-dependent so it's up to the user to decide what works best for their language. For English, the lower this value is the more noise TRACER will generate.
[warning] To update
The value of
intNGramSize[warning] To update
If the value of
weigthByLogLikelihoodRatio(sic!) is set totrue, TRACER will...
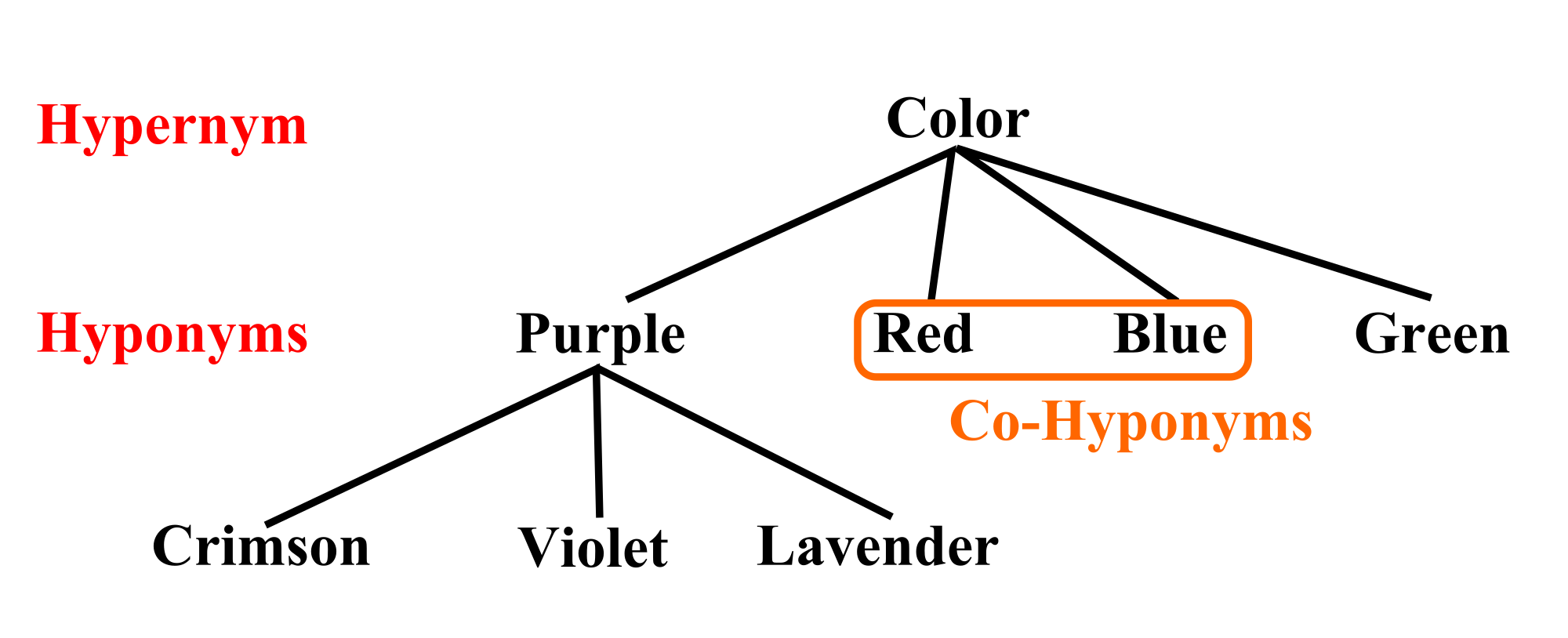
If users want to detect non-literal text reuse, the value of the property boolReplaceSynonyms needs to be true. And although the name of the property misleadingly suggests that TRACER can only work with synonyms, this is not the case. Users can supply TRACER with lists of hyponyms, cohyponyms or even hypernyms if they so wish. The image below explains what these are and their relation to one another.
Customising parameters or properties
To change preprocessing properties simply enable/disable them in the tracer_config.xml as you see fit. For example, to switch off lemmatisation, replace its corresponding value true with the value false and save the changes. Lemmatisation helps to, for example, discriminate nouns from verbs (e.g. the word ‘power’, which can be both a verb and a noun). Lemmatisation is especially important when we wish to analyse paraphrases and allusions. If we wanted to find direct quotations (verbatim or near verbatim), lemmatisation is not going to be useful so we would switch its value in the tracer_config.xml file back to false.
How to read Preprocessing computed files
To view the results of TRACER's Preprocessing step look for files with the .prep suffix in TRACER_DATA. Let’s look at these one by one.
KJV.prep
This is the result file of the preprocessing step. If you look carefully, you’ll notice that sentence 4000001 contains the words get and make, which are the preprocessed versions of the original beginning and created (see Figure 4.9). The lemmatisation settings have erroneously replaced beginning with get and the synonym replacement has changed created to make. These settings can be changed in order to correct any mistakes. Similarly, in sentence 4000006, the archaic term midst has not been replaced with the modern equivalent middle but it could if we wanted! For this reason, it’s important that you thoroughly check the KJV.prep file before moving onto the next step.
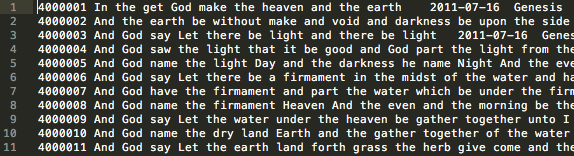
KJV.prep.inv
inv stands for inverted list. It shows you that a specific word (first number) appears in a specific verse (second number) in a specific position (third number).
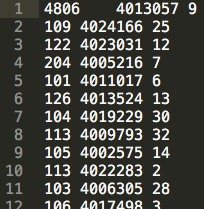
KJV.prep.meta
This file provides overview information about the preprocessing tasks, the settings and the results. For example, it tells us that 103,673 words out of the entire corpus were lemmatised.
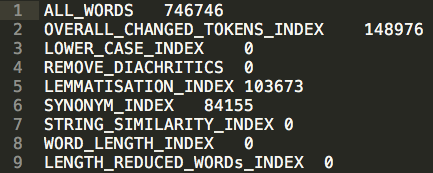
Understanding Preprocessing
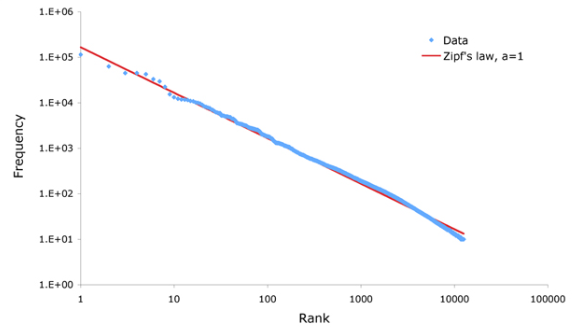
The processing techniques described so far are common practice in Natural Language Processing (NLP). One of the laws of NLP is known as Zipf's Law. According to Zipf, 90% of words in a text are rare, occurring 10 times or less; 50% of all words occur only once; 16% of all words occur only twice and 8% only three times, and so on. This means that the frequency of any word is inversely proportional to its statistical rank. For example, according to wordcount.org, the most popular word in the English language is ‘the’. As such, its rank is 1 (see Figure below).
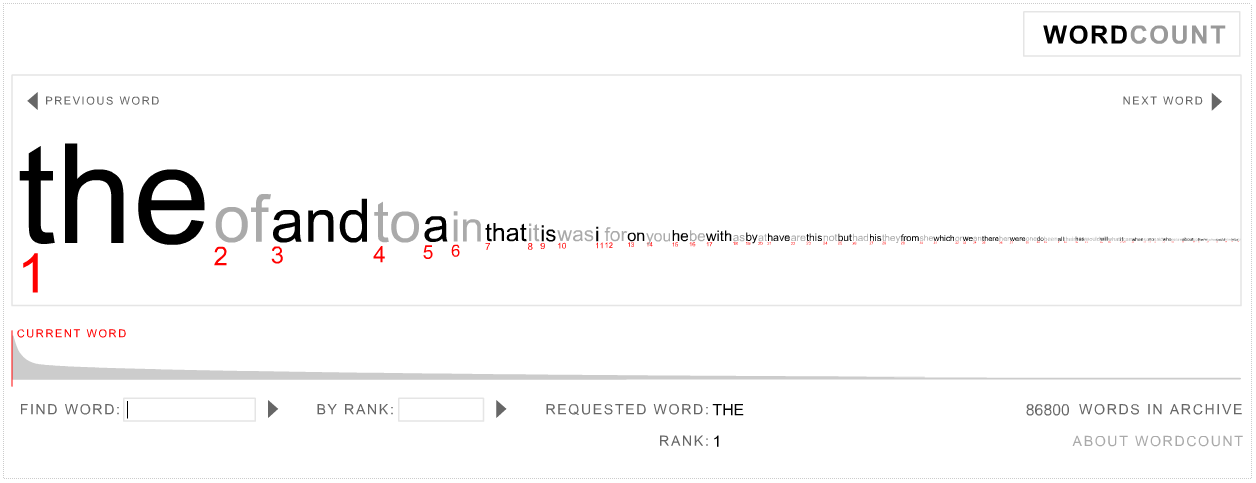
The word 'cat' ranks 2532 and does not appear as often as the word ‘the’ (Figure below).

So, again, the higher the rank, the less frequent theword and vice versa. We can visualise this proportion as a log-log graph, which reveals a 'straight line' relation between word frequency and ranking (Figure below). Amazingly, Zipf’s law applies to all languages.