Text Reuse
At its most basic level, text reuse is a form of written text repetition or borrowing. Text reuse can take the form of an allusion, a paraphrase or even a verbatim quotation, and occurs when one author borrows or reuses text from an earlier or contemporary author. The borrower, or quoting author, may wish to reproduce the text of the quoted author word-for-word or reformulate it completely.
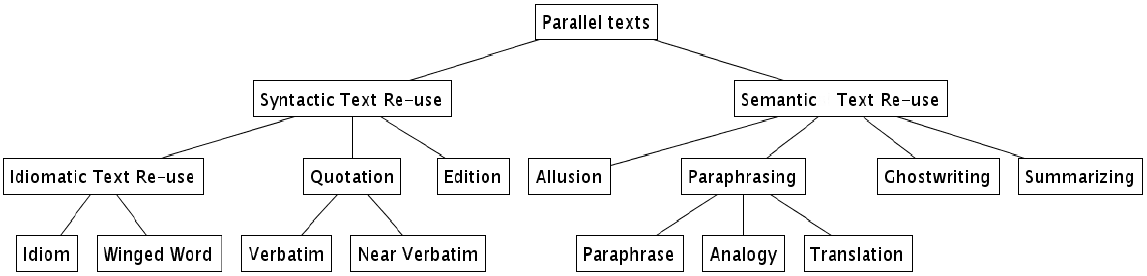
The chart below illustrates the various styles of text reuse we may encounter. Given two or more texts we wish to compare, there are two main branches of text reuse:
- Syntactic text reuse, which includes verbatim and near-verbatim quotations, as well as idioms. This style of text reuse is "easier" for a machine to read and identify.
- Semantic text reuse, which includes looser forms of reuse such as allusion, analogy and paraphrase. These are harder to detect with a machine as they operate at a more semantic level.
Text reuse detection on historical data is particularly challenging due to the fragmentary nature of the texts under investigation and the evolution of language over time.
Growing bibliography
A growing bibliography of historical text reuse is available here (Zotero): https://www.zotero.org/groups/500373/historical_text_reuse?
Discussion group
A historical text reuse forum is available here (Google Group): https://groups.google.com/forum/#!forum/historical-text-re-use