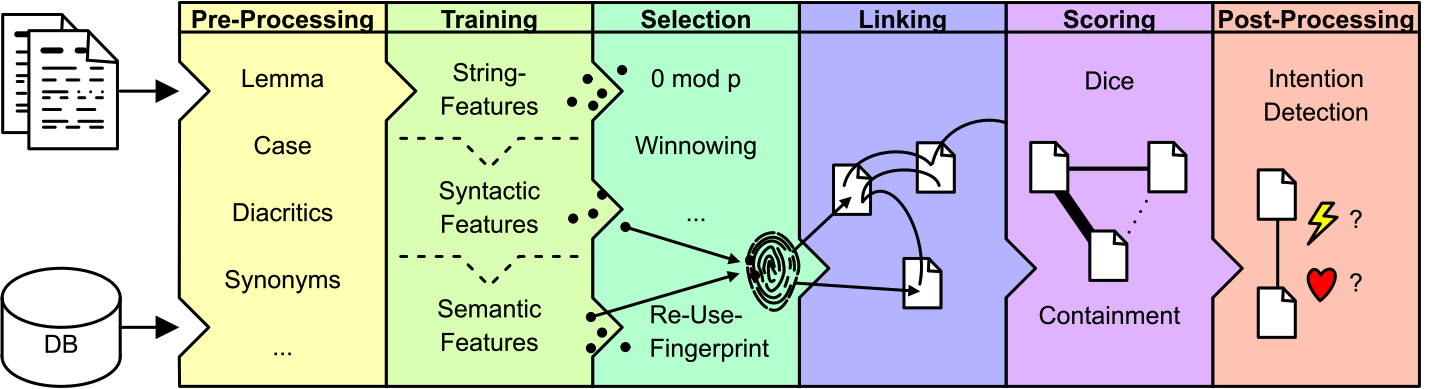
TRACER overview
TRACER is a framework of roughly 700 algorithms, whose features can be combined to create the optimal model for detecting those words, sentences and ideas that have been reused across texts. Created by Marco Büchler during the eTRACES project at the University of Leipzig, TRACER is designed to facilitate research in automatic text reuse detection and many have made use of it to identify plagiarism in a text, as well as verbatim and near verbatim quotations, paraphrase and even allusions. The thousands of feature combinations that TRACER supports allow to investigate not only contemporary texts, but also historical texts. TRACER is a command line engine. The reason it does not come with a user-interface is to boost computing speed. TRACER can use large and remotely-accessible servers, which facilitate the computation of large data-sets. The reuse results can be visualised in a more readable format via TRAViz (see Step 6.Postprocessing).
Current state
TRACER is language independent and has been successfully tested on Ancient Greek, Arabic, Coptic, English, German, Hebrew, Latin and Tibetan. The Publications section of this manual lists reports written by TRACER users. We continuously seek new languages to work with. TRACER has been used on both historical and modern texts. A list of bug reports and current developments is available here.
Under the hood
This manual provides a user-friendly guide to text reuse detection for both novice and expert users. For this reason, it does not give an accurate description of the roughly 700 algorithms constituting TRACER but only the necessary knowledge in order to perform simple text reuse detection tasks. Those who wish to study TRACER’s algorithms in detail should consult TRACER’s Javadoc.
Citation
To cite TRACER, you can adapt the following:
Büchler, M. TRACER: A Text Reuse Detection Machine. DOI: https://doi.org/21.11101/0000-0007-C9CA-3