Corpus preparation
TRACER works with plain text files (.txt). This means that if you have marked-up texts in XML, you must remove all of the XML tags before you can use TRACER. To create and manipulate .txt files, use Sublime Text, as previously recommended.
To optimise the performance of TRACER, place your texts (two or more, depending on how many you wish to analyse) in the same .txt file, one under the other. Placing all texts in a single file is beneficial as TRACER will consider every line as a reuse unit to compare. To distinguish the texts, you will use different IDs (keep reading to find out how to do this).
Segmentation
The first thing you need to do is to segmentise your texts by verse, paragraph, sentence, or whatever unit you believe best suits your reuse analysis. Every unit must appear on a separate line in the .txt file. You can use the free NLTK service to segmentise your text, but this tool will use full-stops as the only cue to identify the end of a sentence. Copy and paste your unsegmentised .txt into NLTK’s text box. Click on the segmentation button, copy the segmentised output and paste it into a new .txt file. Save this new file and give it a clear name, such as mytext-segmentised.txt. Please note that NLTK only takes a certain number of lines, so if you have a very long text you will have to divide it into smaller chunks. Always double-check the output because sometimes formatting errors can sneak in unnoticed.
Column layout
Next, your .txt must contain four columns separated by TABs:
- The first column contains unique sentence IDs.
- The second column contains the sentence.
- The third column can contain the date of the file creation in the
YYYY-MM-DDformat or the wordNULL. If you useNULL, make sure it is written in upper-case. - The fourth column contains the book or section from which the sentence is taken. This information is crucial for the visualisation shown in the Text Reuse Browser figure in Postprocessing. The top drop-down menu you see there will list the information you provide in this fourth column.
You can achieve this column structure in three ways:
- Microsoft Excel or Libre Office
- Python scripts created by Mike Kestemont
- R scripts created by José Luis Losada
The instructions below are based on Libre Office Version 5.1.5.2.
Text preparation with Libre Office
First, you need to import the segmentised texts stored in your .txt file into Excel or Libre. To do so, simply right click on the .txt file, click on Open with and select either Excel or Libre. Alternatively, open Microsoft or Libre, click on File > Open and select the .txt file. Whatever you choose, it’s essential that you specify TAB** as the field separator when importing the file. If you don’t, TRACER won’t be able to read your file. The import window looks something like this:
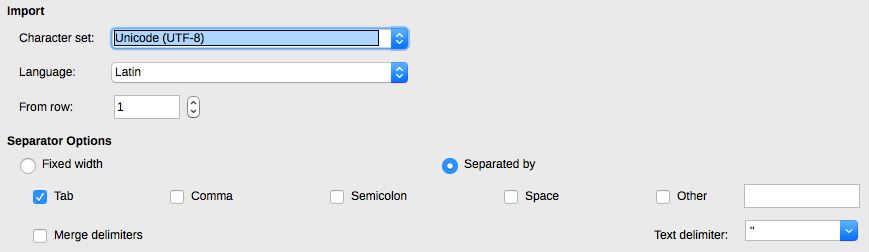
Select TAB in the Separator Options section and click OK. You should now see something like this:
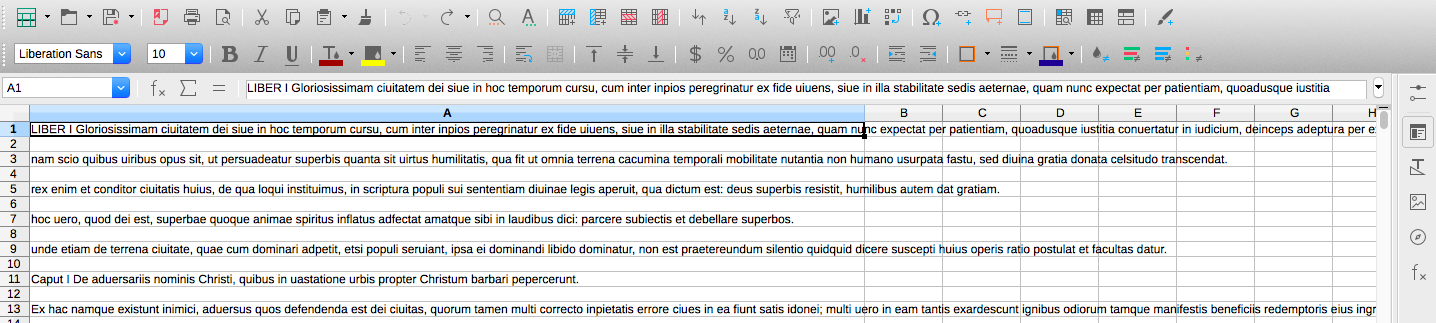
We now need to remove all blank rows. If you’re using Libre, select the entire text column, then click on the autofilter button in the toolbar (it looks like a funnel). This generates a clickable arrow symbol on the first cell. Click the arrow and select EMPTY from the list of options (see image below).

This will bring all blank rows to the top of the document (if you look at the row IDs now you’ll notice that the column only lists even numbers, i.e. alternating blank rows). Delete all of these by pressing the SHIFT button on your keyboard, keeping it pressed while selecting all of the rows, then release the SHIFT button, right-click on the selected rows and click on DELETE. Next, press on the arrow again and select NOT EMPTY. You should now see your text, one sentence per row and no blank rows. Finally, deselect the autofilter button in the toolbar and save the changes.
IMPORTANT: Make sure you remove all blank lines from your file (check the bottom of the file as well) as these will not be correctly processed by TRACER and will cause the detection task to break.
If you’re using Microsoft Excel, select the first column, click on the FILTER button in the toolbar. Again, click on the little arrow that is now available in the first cell. In the new pop-up window you need to do two things: first, click on the SELECT ALL option to deselect all options; second, scroll down to the bottom of the options pane and select BLANKS. This will bring all the empty rows to the top of the document (if you look at the row IDs now you’ll notice that the column only lists even numbers in blue). Delete all the empty rows by pressing the SHIFT button and keeping it pressed while selecting all the blue-numbered rows. Then, deselect the FILTER button in the toolbar and save the changes.
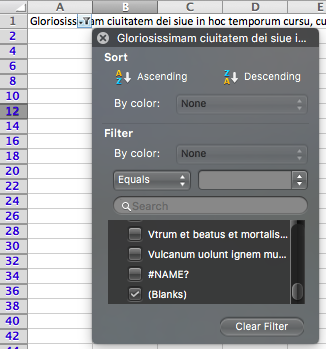
Microsoft Excel’s filter buttons and pane. After deselecting all options within the pane, reselect Blanks in order to delete all blank rows.
Next, add a column to the left of your sentence column. This new column should contain sentence IDs. To automate the creation of IDs, type in the first three IDs (one per sentence), then select the three ID cells, hover over the bottom right corner of the third cell and finally drag the selection all the way down to the last sentence. Remember to save the changes!
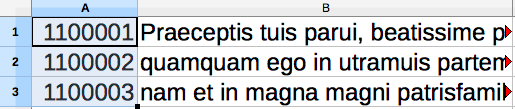
The sentence IDs should be sequential and unique. The default set-up of TRACER requires IDs to be 7-digits in length and numbers below 2,000,000. If you're analysing two texts, make sure to restart the ID sequence for your second text. So, for example:
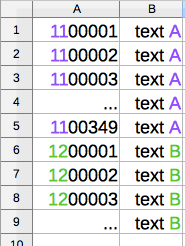
As you can see from the image above, all IDs are 7-digits long and the two different texts to be analysed, A and B, are distinguished via the first two digits of the ID. Next, make sure that the respective ID value in TRACER's configuration file in the Linking section is set to 100,000 and *NOT* 1,000,000.
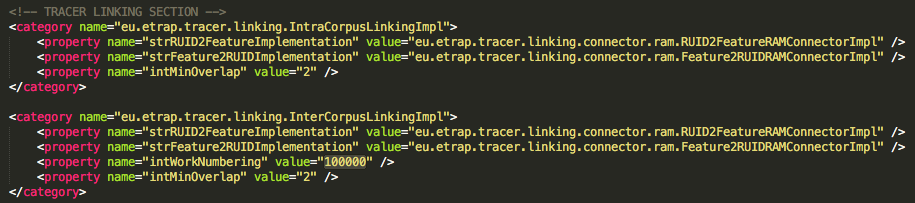
However, doing so is only recommended in consultation with the TRACER team as it may affect the detection process and your results. Moreover, ensure that there are no new blank lines at the end of the document and that there’s no white-space between text A and text B. Any blank lines will bring up errors.
Next, add two columns to the right of your sentence column. In the third column you can either put a date of file-creation (in the YYYY-MM-DD format only) or the case-sensitive word NULL. To populate the entire column with the date or NULL , repeat the drag action used above but from the first cell only, not the third. By dragging from the first the cell values will not increase or change as you move downwards.

The fourth column should list the source of the text, whether it's a book, a chapter or the title of your text. This information is necessary for the text reuse visualisation to work later on. To populate this column repeat the actions described in the previous paragraph.

Save your four-column file as a .csv document. Finally, change the extension of the file from .csv to .txt.
That's it, your text is now TRACER-compatible!
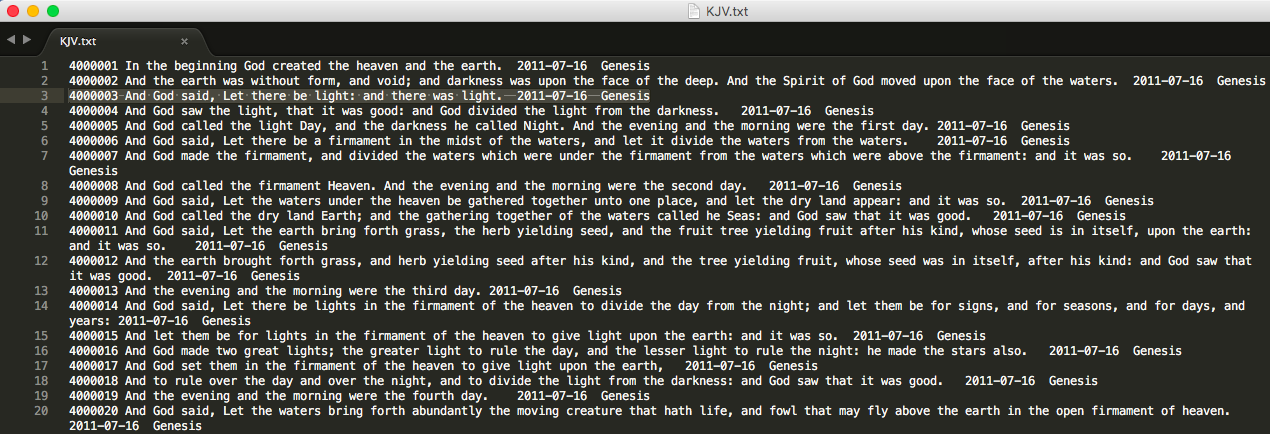
The figure below provides an example of the King James Bible Version text formatted for TRACER.
Where to store your texts
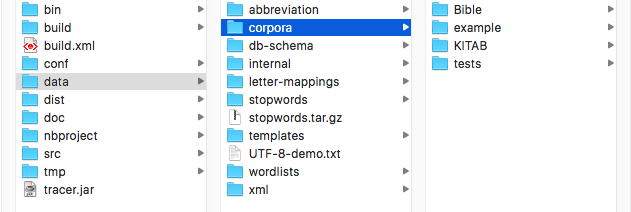
Place your texts in the corpora subfolder of TRACER’s data folder, as shown below:
IMPORTANT: never use white-spaces in file names.
Next, make sure TRACER's configuration file points to your .tx file. For example, if your text file is called KJV.txt, locate the SENTENCE_FILE_NAME property in the configuration file and add the path of your file to the value attribute:
