Step 4. Linking
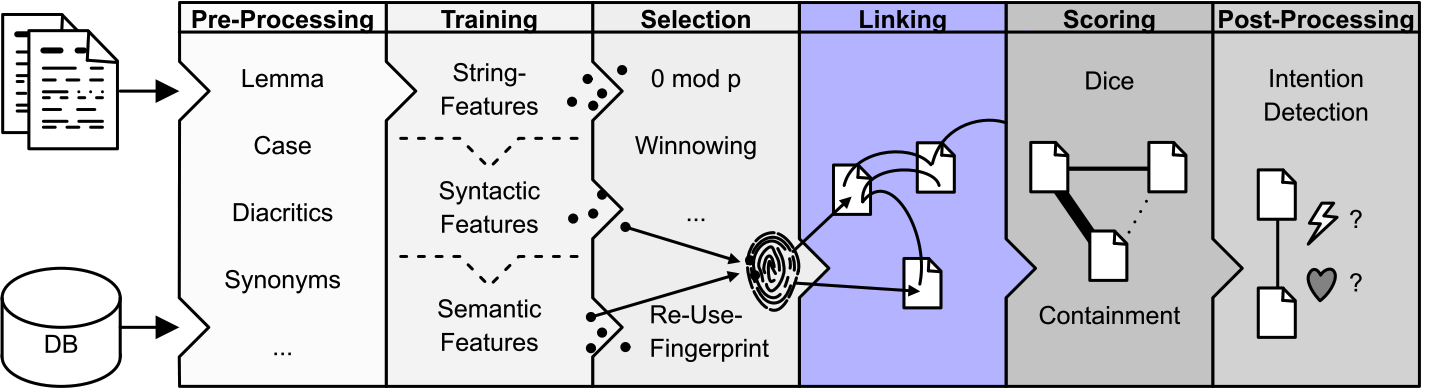
In the Linking stage, TRACER creates links between the features defined in previous steps. Unlike other TRACER steps, which are all linear, Linking is of squared complexity depending on the feature frequency and it is, therefore, the most computationally- and time-intensive task in the detection process. Through Linking TRACER will deliver results based purely on the parameters set in previous steps. It is up to us to interpret those results and filter out what is good and what is bad.
Types of Linking
TRACER can perform two types of Linking, Intralinking and Interlinking.
Intralinking
Intralinking looks for text reuse within the same text or work (i.e. self-reuse). Given Work A below, TRACER will look for a sentence that repeats itself either word-for-word or non-literally in Work A. Intralinking can be used, for example, to analyse a Bible and see how one Gospel reuses another.

Interlinking
Interlinking looks for matches between different texts or works. Given Work A and Work B below, TRACER will look for a sentence that repeats itself in a different work, not in the same work. Interlinking can be used, for example, to compare different Bibles or Bible translations.
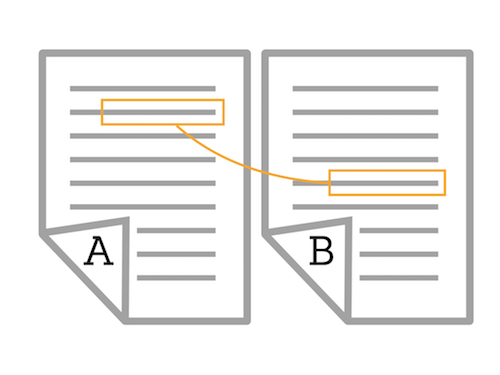
Remember that Edition A and Edition B are actually stored in the same .txt file, one under the other, as described in Corpus preparation. The Inter/Intra parameter can be changed in the TRACER tracer_config.xml:
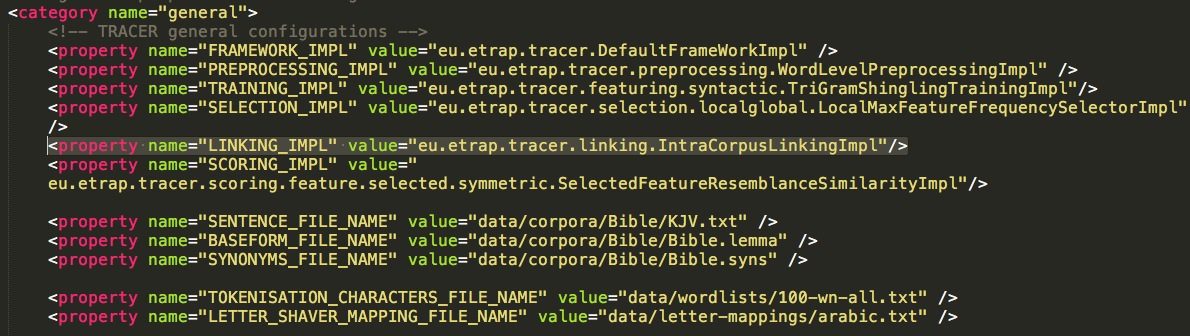
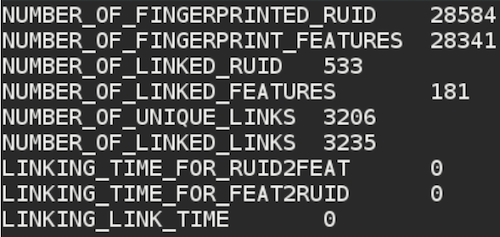
TRACER outputs Linking results in a .link file in a three column structure:
REUSE ID 1 - REUSE ID 2 - OVERLAP
Here’s how this structure looks like in the corresponding file:
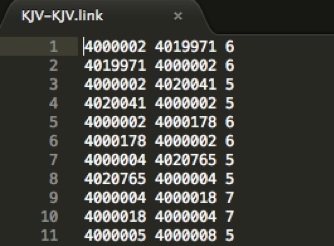
What does TRACER mean by absolute overlap? The absolute overlap is the minimal number of common features shared by the first two columns (REUSE ID 1 and REUSE ID 2), which TRACER sets as default to 5. This overlap number can be changed and is used to cut the long tail of reuses which would likely not be relevant matches or reuses at all. The .meta Linking file will provide you with an overview of the features linked:
Linking is the most time-consuming step and the step that can be best parallelised, as shown in the chart below.
Moving Window Linking Implementation for short reuse
The two types of Linking implementation described above work well when linking text reuse units (e.g. sentences) of a similar size and for detecting close reuse or rewording (i.e. where the reuse covers roughly more than 50% of the unit). One example of where we could use these implementations is the Bible: we could, for instance, compare Mark with Luke. The reuse units, the verses, are similar in length and our knowledge of the Bible tells us that Luke copied from Mark. If, however, you’re looking for paraphrase or allusions, or if the reuse covers less than 50% of the unit, these two implementations will not perform well. That is not to say that you can’t use them. But if you do, you must lower the similarity thresholds in the tracer_config.xml file, and by doing so TRACER will contaminate your results with many false positives.
For these cases, TRACER provides another Linking implementation, the Moving Window. This approach is well-suited, if not necessary, for the detection of very small reuse; for example, to detect a four-word overlap in two sentences (as reuse units) of 20 and 25 words each. If we set a Moving Window of, for example, 10 words, TRACER will read the reuse unit 10 words at a time with a one-word overlap, as shown in the Latin example below:

If you don’t know your data well and would like TRACER to give you a rough idea of the degree of similarity between two or multiple texts, the recommendation is to first run a detection task without the Moving Window implementation in order to detect the closest matches. Use the Moving Window only if the result-set or recall from this first analysis is too low and/or if you’d like to find smaller reuse.
To use the MovingWindowimplementation, you first need to segmentise your reuse units into windows. We recommend you try with windows of 10 or 15 words as these should detect most reuses. But you may, of course, run more than one detection with bigger or smaller window sizes and compare the results!
First, ensure your corpus .txt file is in TRACER’s corpora folder. Then, in the terminal, navigate to TRACER’s main folder and type this command:
java -cp tracer.jar eu.etrap.tracer.preprocessing.MovingAverageSegmentizerMain data/corpora/YourCorpus/yourcorpus.txt 15
Where the data/...yourcorpus.txt path points to the location of your text in TRACER’s data folder and 15 tells TRACER to split reuse units into windows of 15 words. Press ENTER and wait a few seconds for TRACER to compute the result. This command creates a version of the yourcorpus.txt where reuse units are formatted into 15-word windows. This file version is automatically named yourcorpus-W15.txt and saved in the TRACER corpora folder. If you want to break the text into windows of 10 words, change the final 15 to 10 in the java command.
Next, you need to make some changes in TRACER’s configuration file. First, make sure that the SENTENCE_FILE_NAME property points to your new yourcorpus-W15.txt file (as described in Corpus preparation). Next, locate the Linking property in the tracer_config.xml file and ensure you have the right class, MovingWindowInterCorpusLinking or MovingWindowIntraCorpusLinking (depending on whether you want to run Inter- or Intracorpus linking):

Next, define the length of your Window in the Linking category of the tracer_config.xml file, in the intWindowSize property:

The value of the intWindowSize property must match the window size you defined in the previous java command.
Save the changes and run TRACER!