Step 5. Scoring
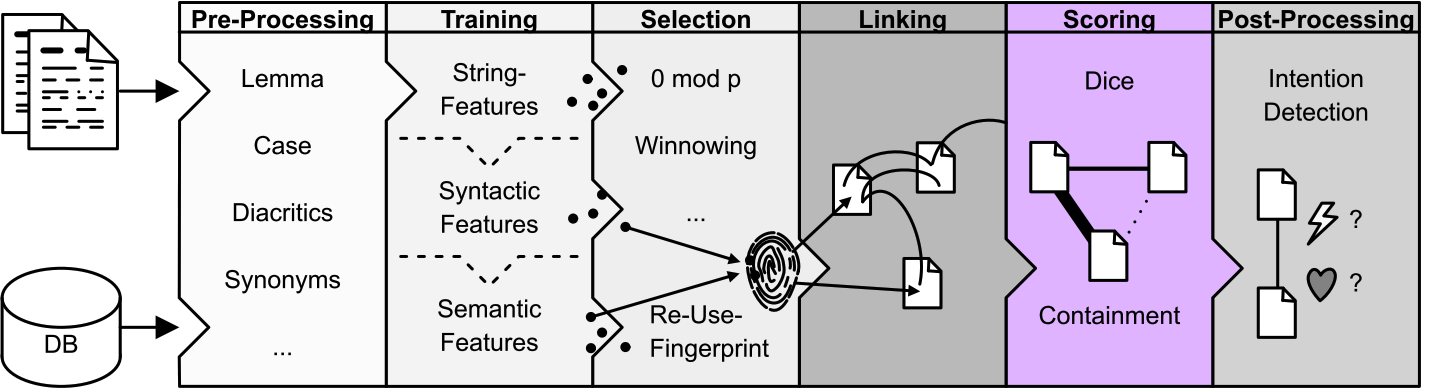
The Scoring step of TRACER assigns a weight to a reuse pair based on an internal scoring metric. The resemblance score is calculated as follows:
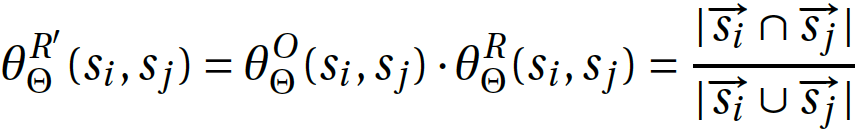
[warning] To update
The resemblance score θ (theta) is the quotient of the reuse overlap (∩) and the reuse union (∪), where the reuse overlap represents the digital fingerprint of reuse units that appear in two candidate strings/lines, and the reuse union represents the number of all digital fingerprints.
The extension of the file in which the scores are recorded is .score. This file contains four columns of data, for example:
4000237 4010258 13.0 1.0
The first two numbers represent two aligned sentences, a sentence in Text A with the ID 4000237 and its reused version in Text B with the ID 4010258. The third number is an absolute overlap, indicating that the two sentences share 13 features (e.g. 13 words, if the user set the Featuring to WordBased). The fourth number is the weighted overlap or the percentage of similarity between the two sentences - in this case, 1.0 means 100% similar, indicating that Text B reused Text A word-for-word (verbatim); a weighted overlap of 0.9 is 90%, 0.8 is 80% and so on.
The Scoring section of the tracer_config.xml file contains three categories:
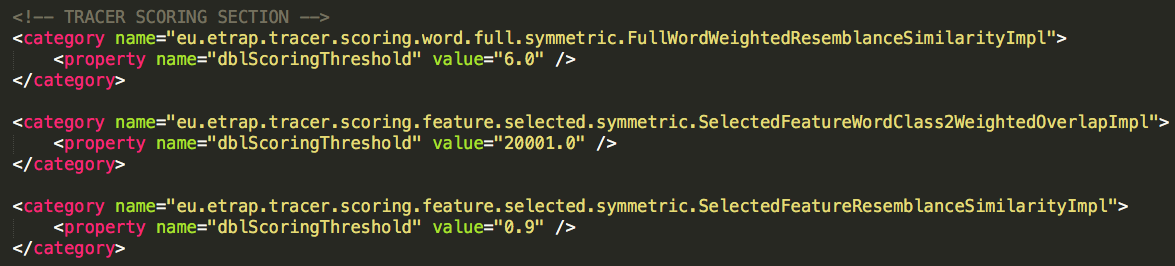
FullWordWeightedResemblanceSimilarityImp: this class computes similarities including all words in the sentence and assigns the same weight to every word. This implementation was designed to deliver results in a human-readable way (i.e. for GUIs).Full-weightedmeans that the similarity score is multiplied by the feature overlap in order to convey some form of confidence; the value of this property here is no longer a scale between0and1but the weight depends on the length of the segmented unit the user chose.SelectedFeatureWordClass2WeightedOverlapImpl: with this implementation selected features are transformed into word classes, and the word classes are weighed. More weight is given to content classes (verbs, nouns, etc.) than to, for instance, articles.SelectedFeatureResemblanceSimilarityImpl: given selected features from a reuse pair (max pruning without function words) this Scoring implementation compares the selected features and gives all words the same weight. The value of this property can range between0and1. If the user sets a high value, such as0.9, TRACER will return reuse pairs that are 90% similar (near-verbatim).
Containment measure for imbalanced length of reuse
If the text segmentation you used has created reuse units of very different lengths, chances are that TRACER will produce many false positives or not be able to match a string in text A against a string in text B at all (= false negatives). Here is an example of text reuse in Latin texts that was not identified by TRACER due to very different reuse unit lengths caused by text segmentation:
Despite the fact that Text B is quoting TEXT A word for word, the different length of the reuse unit (that is, the sentence within which the text reuse appears) coupled with configuration parameters set for this particular analysis eluded TRACER.
To avoid this from happening, we must change the default Scoring SelectedFeatureResemblanceSimilarityImpl property value in tracer_config.xml to SelectedFeatureContainmentSimilarityImpl, as so:
